Loading blog post...
Spotify is a leading music streaming service founded in 2006 in Sweden, now serving over 500 million monthly active users worldwide as of 2025. It provides access to millions of songs, podcasts, and audiobooks through free ad-supported and premium subscription models. The platform's success hinges on seamless streaming, personalized recommendations, and scalability to handle billions of daily events like plays, skips, and searches. This case study explores how Spotify operates, with a focus on its event-driven architecture, why it's superior, audio formats and sound quality, and overall system design. We'll delve into technical details, supported by diagrams from reliable sources.
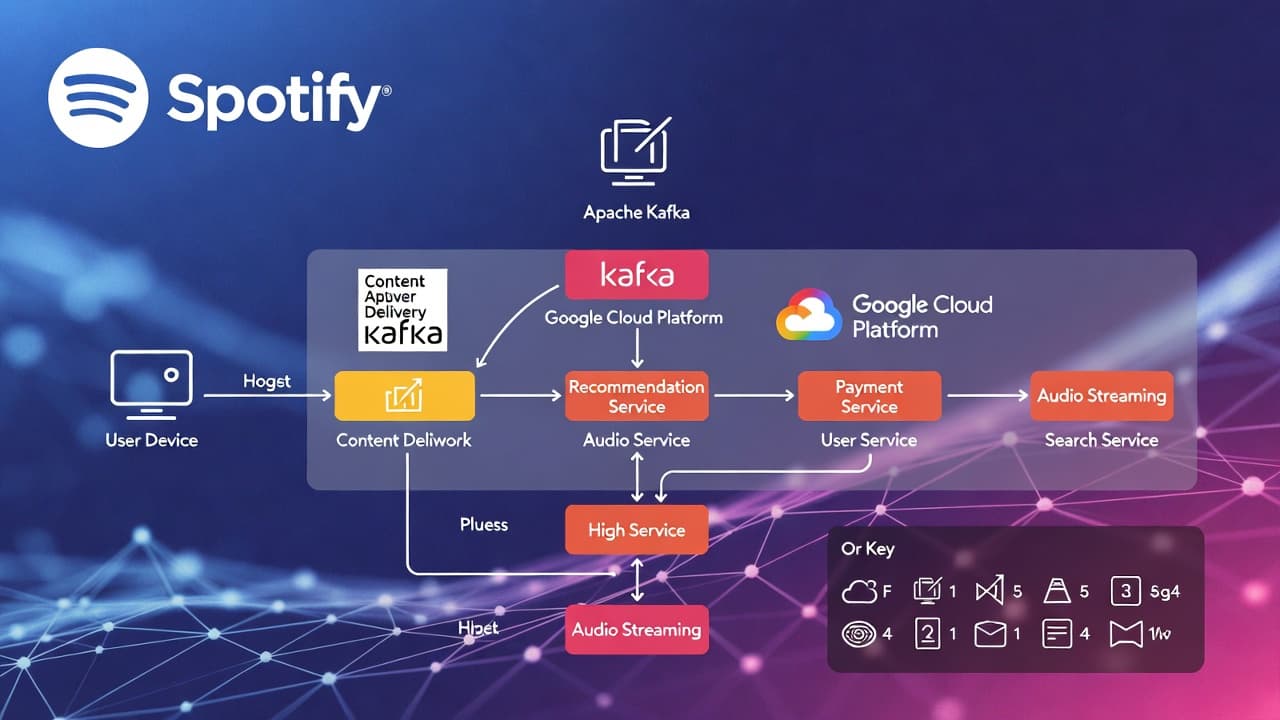
At its core, Spotify functions as a distributed system that delivers audio content on demand while processing user interactions in real time. Here's a step-by-step breakdown:
User Interaction: Users access Spotify via mobile apps, desktop clients, web players, or connected devices. They search for content, create playlists, or receive recommendations.
Content Delivery: Audio files are stored in cloud object storage (e.g., Google Cloud Storage or AWS S3) and distributed via Content Delivery Networks (CDNs) like Amazon CloudFront for low-latency streaming. When a user plays a track, the client requests metadata (e.g., song details) from backend services and streams the audio in chunks.
Personalization and Data Processing: Every action (e.g., play, skip, like) generates events that feed into machine learning models for recommendations. These events are processed asynchronously to avoid blocking the user experience.
Backend Operations: Services handle authentication, billing, analytics, and content management. Premium features like offline downloads and higher quality audio are gated by subscription status.
Scalability Mechanisms: Spotify handles peaks of over 10 million requests per second through horizontal scaling, caching (e.g., Redis), and load balancing (e.g., NGINX).
This setup ensures reliability, with features like offline mode caching data locally and syncing when online.
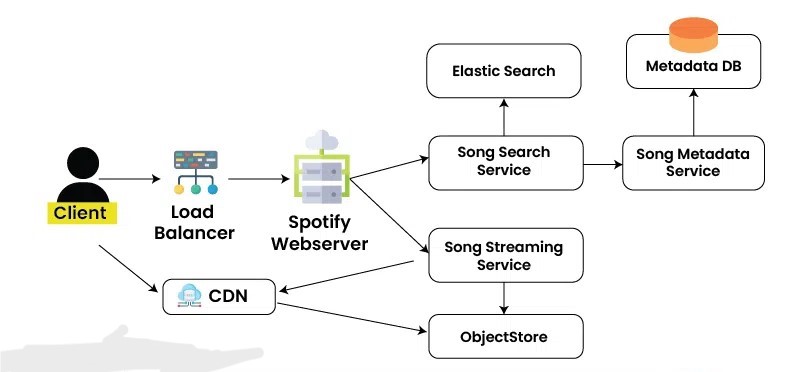
Spotify employs a microservices architecture, breaking the monolith into hundreds of independent services. Each service (e.g., user authentication, playlist management, recommendation engine) is owned by autonomous teams, allowing independent deployment and scaling. This contrasts with monolithic designs where changes affect the entire system.
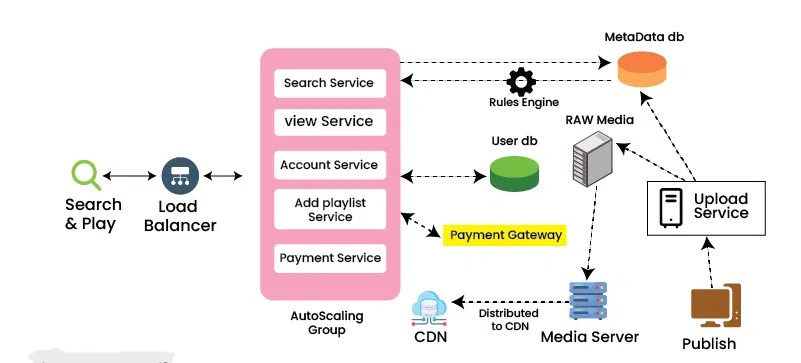
Key components include:
Frontend: Built with HTML/CSS/Bootstrap for web, and native frameworks for apps. Requests route through load balancers (NGINX) and API gateways.
Backend Services: Use languages like Java, Python, and Go. Services communicate via RESTful APIs or message queues.
Databases:
Relational (PostgreSQL) for structured data like user profiles.
NoSQL (Cassandra, Hadoop) for big data analytics.
Search (Elasticsearch) for fast queries on songs/artists.
BigQuery for analytics.
Caching and Proxy: Redis for session data, Hystrix for circuit breaking to prevent cascading failures.
Billing and Analytics: Integrated with tools like Google BigQuery and Cassandra for processing user events.
Audio File CDN: Amazon CloudFront or similar for global distribution of audio files.
Authentication: OAuth/JWT with IAM (Identity and Access Management).
This includes the API gateway, proxy, Kafka integration, and databases.
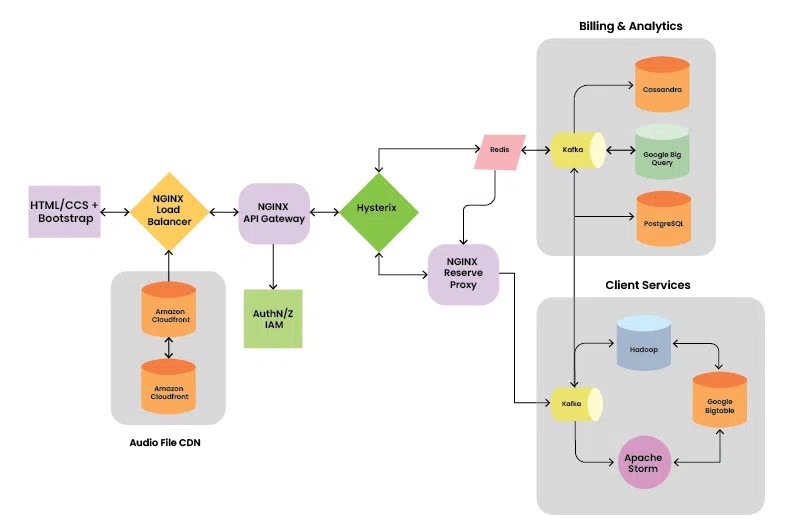
Spotify's system is heavily event-driven, using Apache Kafka as the backbone for streaming and processing events. In an event-driven system, components communicate by producing and consuming events rather than direct calls, promoting loose coupling.
How Event-Driven Works in Spotify
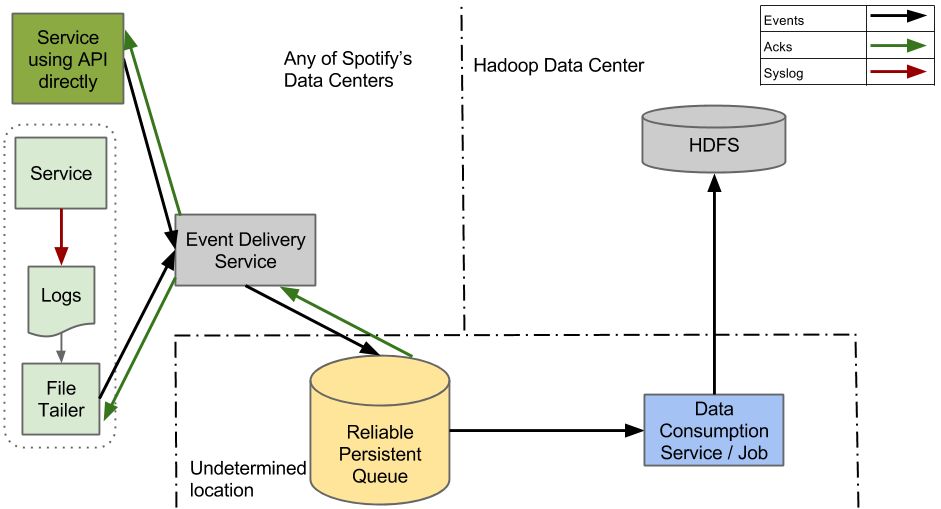
Event Generation: Services log events (e.g., "user skipped track") to files or directly via APIs.
Ingestion: A "File Tailer" reads logs and sends them to the Event Delivery Service.
Processing: The Event Delivery Service transforms events into structured formats (e.g., Avro schemas) and forwards them to a reliable persistent queue (Kafka topics).
Distribution: Kafka brokers distribute events across datacenters. Consumers (microservices) subscribe to topics for real-time processing.
Consumption: Downstream jobs (e.g., ETL for analytics) pull events, storing them in HDFS or databases. Checkpoints ensure no data loss.
Monitoring: Tools like Kafka checkpoints monitor liveliness and acks (acknowledgments).
Spotify processes over 2.5 billion events daily for personalization. They evolved from an older syslog-based system to a cloud-native one using Google Cloud Pub/Sub as a Kafka alternative in some parts.
In Kafka terms:
Producers: Services sending events.
Brokers: Kafka clusters handling topics (partitioned for scalability).
Consumers: Microservices or jobs subscribing to topics, often in groups for load distribution.
This setup supports real-time features like "Discover Weekly" playlists, where ML pipelines consume events to train models.
Event-driven designs offer several advantages over traditional request-response models, especially at Spotify's scale:
Decoupling: Services don't depend on each other's availability. If a recommendation service fails, streaming continues unaffected.
Scalability: Kafka handles high throughput (millions of events/sec) with horizontal scaling. Partitions allow parallel processing.
Resilience: Events are persisted durably; consumers can replay them if needed. This reduces data loss during failures.
Real-Time Processing: Enables instant analytics and personalization without batch jobs delaying insights.
Flexibility: New services can subscribe to existing topics without modifying producers, easing evolution.
Drawbacks include complexity in managing event schemas and ensuring ordering, but Kafka's features (e.g., exactly-once semantics) mitigate these. Compared to synchronous microservices, event-driven reduces latency spikes and improves fault isolation.
Spotify streams audio in the Ogg Vorbis format for most quality levels, switching to FLAC for lossless. This codec is efficient, offering better quality than MP3 at similar bitrates due to superior compression.
Sound Types and Quality Levels
Free Tier: Up to 160kbps (High) on desktop/mobile, 128kbps on web. Uses AAC on web.
Premium Tier:
Low: ~24kbps (basic, data-saving).
Normal: ~96kbps (balanced).
High: ~160kbps.
Very High: ~320kbps (near-CD quality, with rich bass, clear treble, wide soundstage).
Lossless: Up to 24-bit/44.1kHz FLAC (studio-quality, no compression artifacts; bit-perfect reproduction).
Podcasts are at ~96kbps (128kbps on web).
Higher bitrates mean more data per second, preserving details like dynamic range and frequency response. At 320kbps Ogg, it's "transparent" (indistinguishable from lossless for most listeners). Lossless shines on high-end setups, capturing nuances up to 22kHz frequencies.
Why these works better -
Bit Depth/Sample Rate: Lossless uses 24-bit (vs. 16-bit CD) for greater dynamic range (less noise), and 44.1kHz sampling for full audible spectrum.
Compression: Lower bitrates introduce artifacts (e.g., dull highs at 96kbps). Premium's 320kbps minimizes this.
Device Impact: Quality is best on wired headphones; Bluetooth limits to ~300kbps. Spotify adjusts automatically but allows manual settings.
Compared to competitors:
Tidal: Up to 24-bit/384kHz (superior for audiophiles).
Apple Music: Hi-Res up to 24-bit/192kHz. Spotify's lossless is capped at 44.1kHz, but sufficient for most music.
Spotify faces issues like data consistency across microservices and high cloud costs. They've adopted tools like the C4 model for architecture visualization to maintain overviews. Future enhancements may include deeper AI integration and expanded lossless support.