Loading blog post...

Why every GPU at the edge is slowly choking
Picture a humanoid robot charging through a warehouse at 2am. dodging boxes, reading shadows, planning every grip and step in real time. A GPU trying to do this would be throttling hard at 60–300W, fans screaming, battery dead in minutes.
The problem isn't software. It's the fundamental architecture underneath. Every CPU, GPU, and ASIC we've built follows the von Neumann model — memory lives in one place, computation happens somewhere else, and data has to travel between them constantly. At the edge, that data movement alone eats 90% of your power budget.
Your brain runs full perception, planning, and motor control on roughly 20 watts by computing right where the memory lives. That's the trick we've been missing.
Dense frame-based neural networks can't fix this no matter how much you shrink the chip node. But spiking neural networks? They're copying biology's playbook — and it's finally working.
How spiking networks actually work
Regular neural nets crunch through massive matrix multiplications on every clock tick, even when nothing interesting is happening in the input. Spiking Neural Networks (SNNs) don't do that.

Each neuron acts like a leaky bucket. Inputs (from spikes upstream) slowly fill the membrane voltage. When it hits a threshold. it fires. Then resets. That's it. The key insight is that information lives in the timing of spikes, not in huge floating-point tensors.
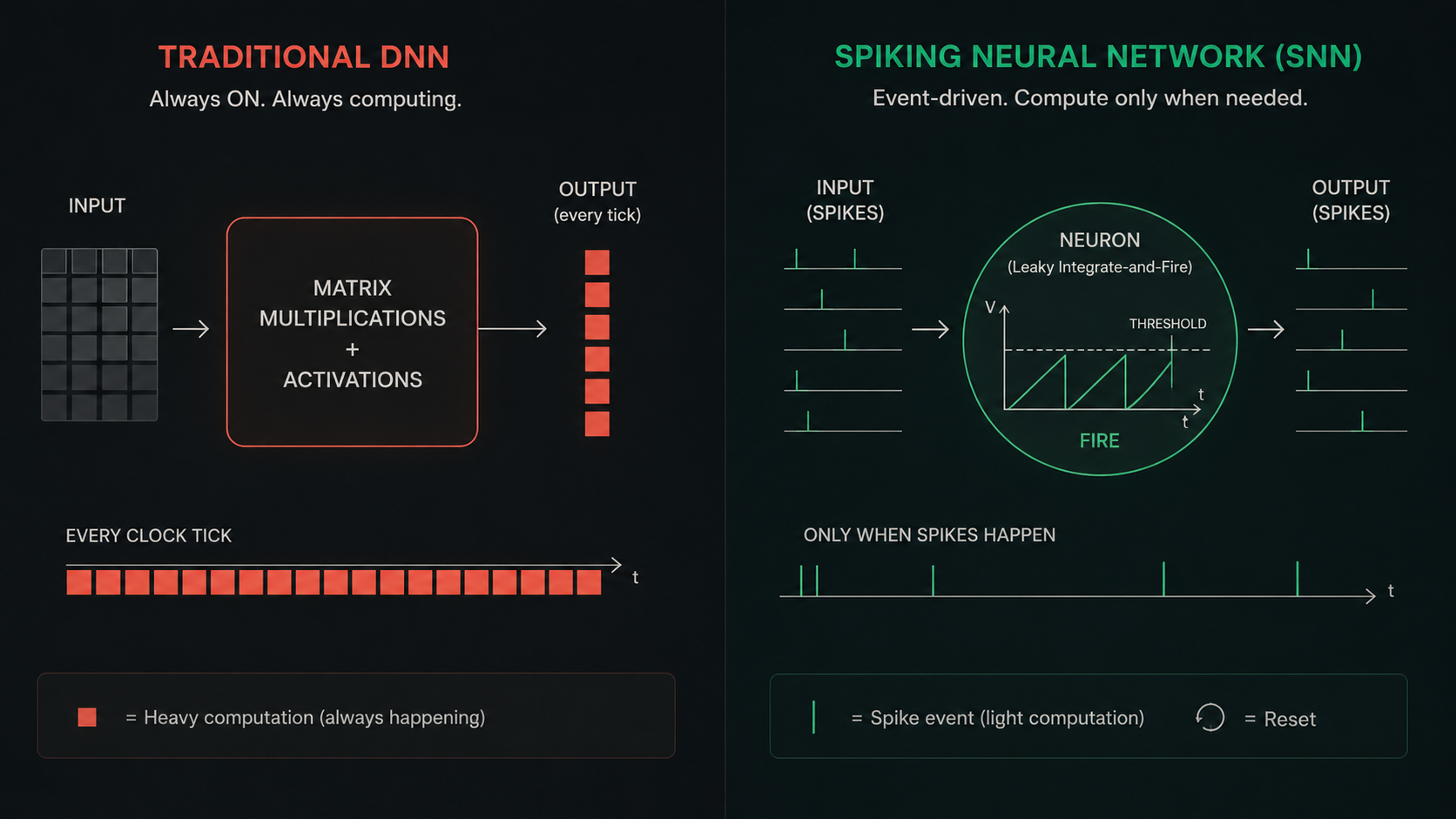
Power that scales with what's actually happening
Traditional cameras sample every pixel, every frame, even when nothing moves. Event cameras work differently. They fire an asynchronous packet: "pixel (x, y) just changed at t=42.317ms."
Downstream neurons only wake up for those events. Everything else draws zero power. In a real warehouse or drone flight, less than 5% of pixels change per millisecond. That's your power budget slashed by 95% before you've even started.
Intel's Loihi 3 and IBM's NorthPole are built around this principle. NorthPole's benchmark on ResNet-50 showed 25× better energy efficiency than 12nm GPUs — and actually beat 4nm GPUs on latency too. A quadruped robot that ran for 8 hours on GPU-based perception ran for 72 hours on Loihi doing the same job.
Synapses that actually learn
Here's where it gets genuinely exciting. Real brains don't ship with frozen weights. They adapt locally, constantly, based on timing. The rule is called Spike-Timing-Dependent Plasticity (STDP): neurons that fire together, wire together, down to the millisecond. If a presynaptic spike arrives before a postsynaptic one (causal order), the synapse strengthens. If after, it weakens. Simple, elegant, biological.
The 2026 version that's actually being deployed is called Triplet STDP and it's significantly more powerful. Instead of looking at pairs of spikes, it looks at triplets (two pre + one post, or one pre + two post). This captures how real synapses behave at different firing rates, not just in isolated pairs.
Triplet STDP has built-in homeostasis. In noisy, chaotic real-world environments (shaky robot arms, windy drone flights), standard STDP diverges. Triplet STDP stays stable.On temporal tasks like gesture recognition and terrain adaptation, triplet variants show 10–20% better accuracy with zero cloud retraining.
Loihi 3's programmable learning engine supports exactly this - multi-trace triplet rules, at picojoule cost. You also get Reward-Modulated STDP (add a dopamine-like signal to turn unsupervised updates into on-chip reinforcement learning) and adaptive variants that automatically scale learning rate so weights don't explode or vanish.
Memristors: the hardware that does math where data lives
A memristor is memory and resistor in one device. Stack them in a crossbar array and you get something magical: apply voltages to the rows, read currents from the columns — and physics has already done the entire matrix multiplication for you. No data movement. No fetch-multiply-writeback loop.
The equation is: I = V × G across every row-column intersection, summed in one shot. That's your entire neural layer computed in a single physics operation.
Digital approximations (Loihi 3, NorthPole) already hit 15 TOPS/W on sparse workloads - 250–1000× better than GPUs for robotics vision. True analog memristive devices push further: zero idle leakage, multi-level conductance (4–8 bits per cell), and crossbar arrays at 1024×1024 or larger in research fabs today.
Where it's still rough
Analog noise accumulates across layers. Conductance drifts 10–30% after 10⁸ write cycles. Fabrication mismatch means every neuron is slightly different. Effective precision caps at 4–6 bits. Cycle endurance hits ~10⁸ for most materials while biological synapses do 10¹⁵+ updates over a lifetime.
These are real limitations. But digital-hybrid architectures (Loihi 3's 8M neurons at 1.2W with 32-bit graded spikes for hybrid DNN-SNN workloads) are already working around most of them. Better materials, 3D stacking, and on-chip calibration are closing the gap fast.
The next 2 years: what to actually watch
Loihi 3 shipping now (Q1 2026) - Intel sampling to robotics OEMs. First time neuromorphic leaves the lab at scale. Triplet STDP, hybrid DNN-SNN, 32-bit graded spikes.
Gartner names AI Supercomputing Platforms a top trend - Hybrid fabrics routing sparse workloads to neuromorphic tiles and dense matrix ops to GPUs. This is becoming infrastructure, not research.
Quantum-neuromorphic hybrids - Quantum co-processors optimize STDP parameters or solve combinatorial planning, then hand tuned weights to an edge Loihi chip. Early results show 100× faster adaptation.
2028 target: mainstream battery-powered humanoids - The physics are in place. Sparse spikes + in-memory compute + triplet timing rules. The question is materials and tooling, not fundamentals.
Ready to try it yourself?
Intel's Lava framework lets you build LIF + triplet-STDP networks on real event data today. If you're still burning GPU watts on edge perception, this is worth an evening.