Loading blog post...

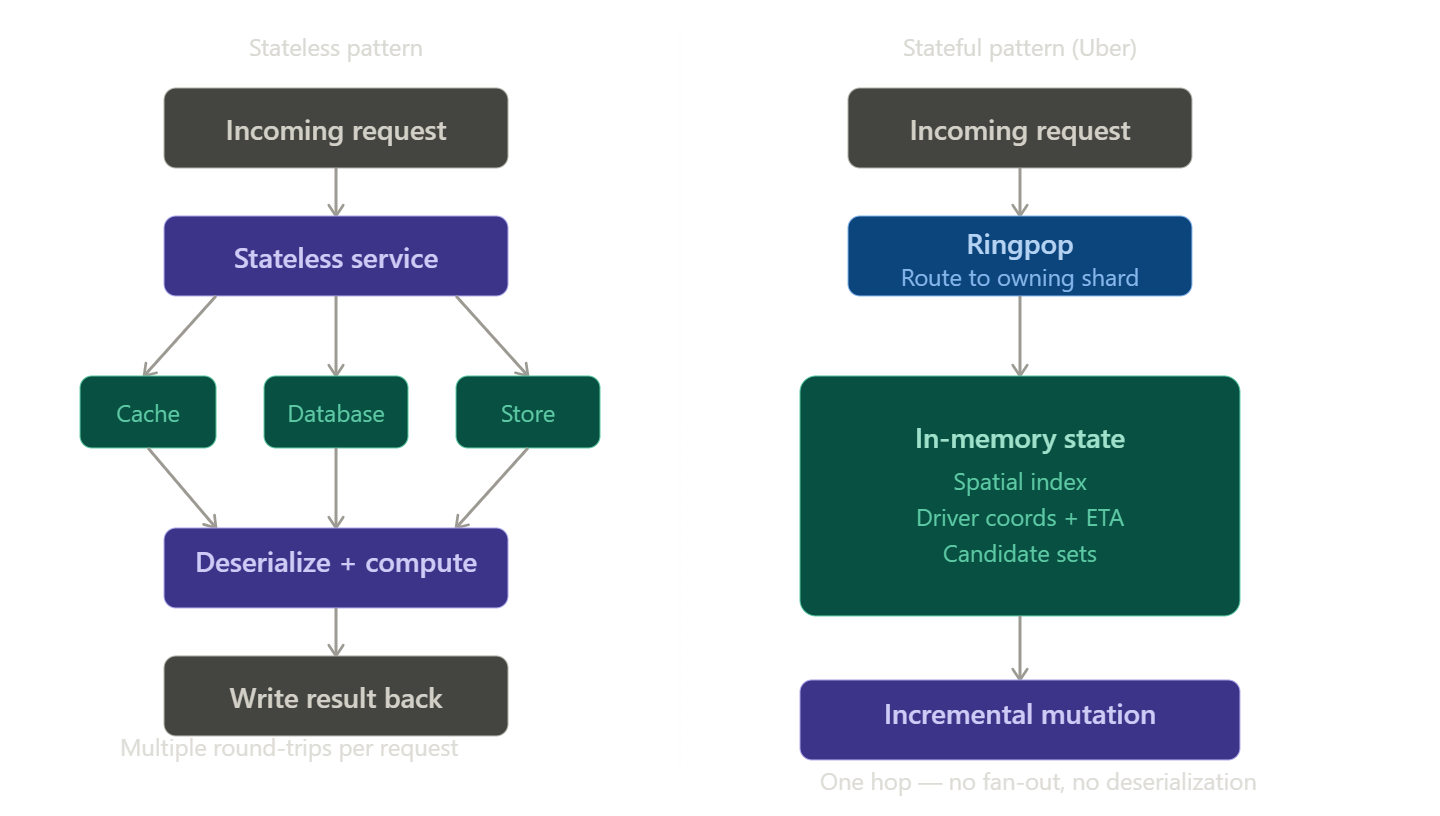
The standard microservice pattern is stateless by design. A request arrives, fans out to caches and databases, deserializes data into an in-memory object graph, computes a result, persists it, and returns a response. At moderate scale, this is a well-understood, horizontally scalable model supported by virtually every cloud-native tool available.
At extreme scale, the regime Uber operates in, starts to break down. The latency budget for each step compounds quickly. For systems tracking the real-time positions of hundreds of thousands of drivers, evaluating dispatch candidates across a constantly-shifting spatial landscape, and responding to trip requests in milliseconds, the stateless fan-out model introduces too much overhead to be viable.
The core tension: every network round-trip, deserialization pass, and cache lookup is a tax paid on each request. At high QPS, that tax accumulates faster than throughput can grow.
Keeping state in application memory
Rather than round-tripping to external data stores on every request, several of Uber's core systems - dispatch, marketplace, and geospatial keep their working state resident in application memory. These services operate closer to the mental model of a database than a typical API server: they own their data, manage their own concurrency control, and serve reads and writes directly from memory.
Uber's Geospatial service was the first major use case. Pinged continuously with driver location updates, it must search those locations for nearby ride requests in real time. A traditional database-backed architecture would be useless here. The data is too ephemeral, and the access patterns too specialized.
Why not cache the pre-built model?
Caching a pre-built in-memory model works when the underlying data is relatively stable. Uber's data is not. Driver positions update every few seconds. Trip requests appear at unpredictable locations. Courier availability shifts constantly. A cached model becomes stale almost immediately, and invalidating and rebuilding it at that frequency defeats the purpose of caching.
Why not use a generic database?
General-purpose storage systems are optimized for a broad class of workloads. That generality has a cost: when a driver's position changes, a stateless service backed by a generic database must fan out to one or more stores, retrieve relevant records, deserialize them into an object graph, recompute match rankings across nearby candidates, and write everything back through the store's write path. Each of those steps involves overhead paid on every update, regardless of how small the change is.
A purpose-built in-memory model eliminates that overhead by enabling incremental mutation. When a location update arrives, the service updates only the specific structures that depend on that change - the driver's coordinates in the spatial index, their availability state, ETA metadata, and any nearby candidate sets requiring re-ranking. No fan-out, no deserialization, no full recomputation.
Ringpop: distributing stateful services
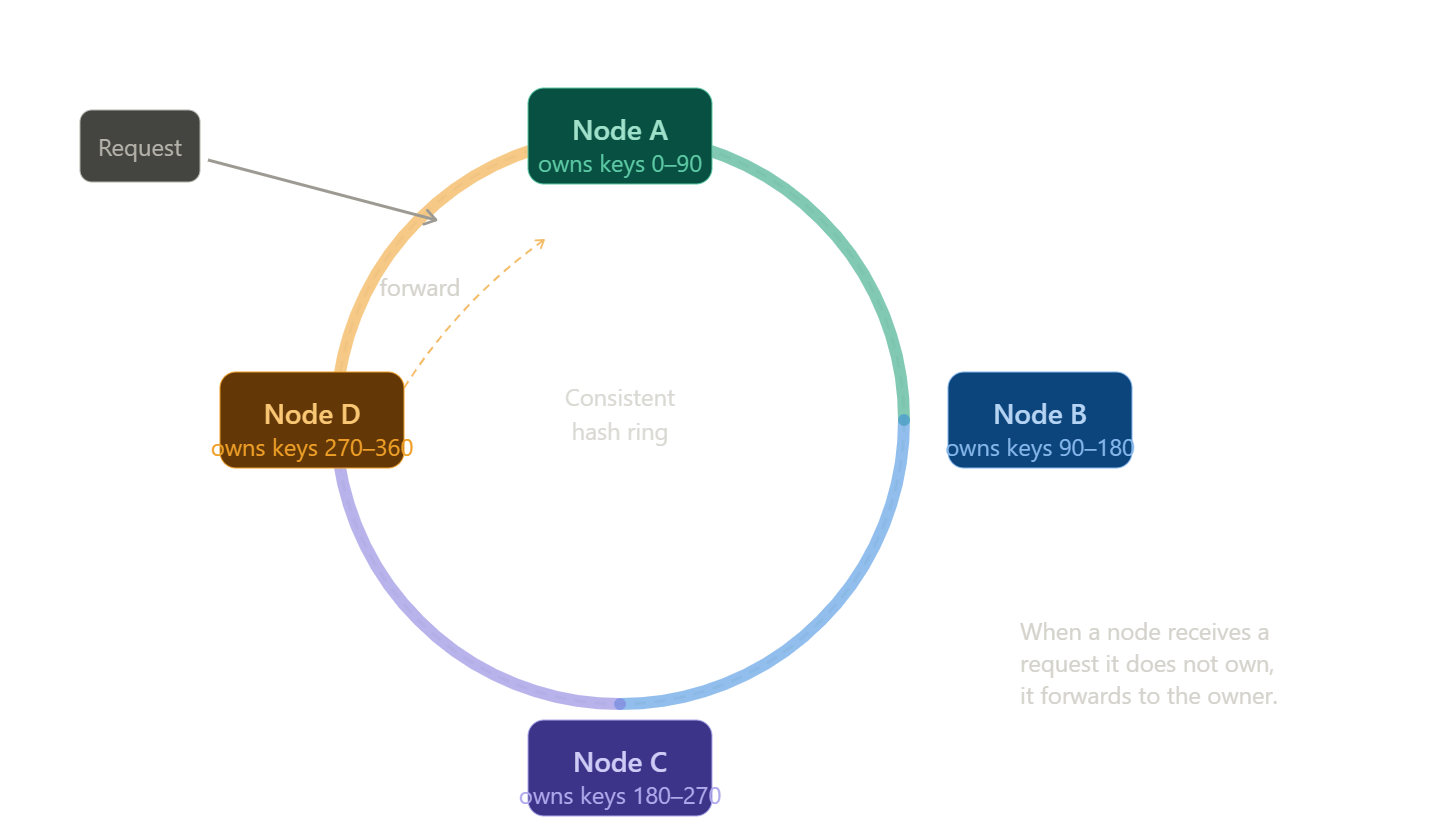
Stateful services raise an obvious question: how do you scale horizontally without externalizing state? Uber's answer was Ringpop, an open-source library that implements consistent hashing to shard state across a cluster of nodes.
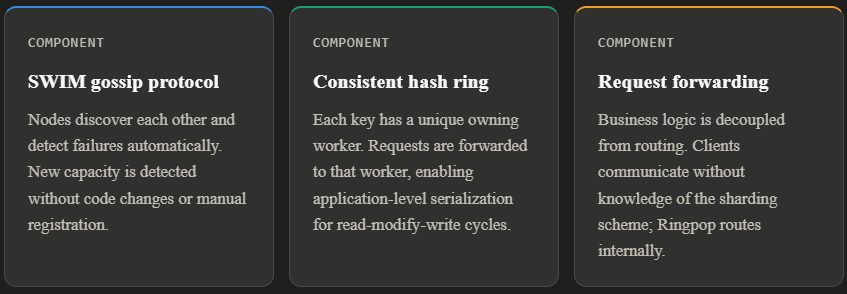
The consistent hashing approach means that when a node leaves the cluster, only the objects in that node's keyspace need to be reassigned to the next node on the ring, rather than triggering a full rebalance. This is the same fundamental technique used by distributed databases like Cassandra and DynamoDB, applied at the application layer.
Ringpop also enabled fine-grained concurrency control. Each worker processes requests for its owned keyspace sequentially, using an in-memory lock and serial queue. This avoids the generalized row-level or document-level locking of a database engine, reducing unnecessary blocking on unrelated in-flight operations that happen to share the same storage partition.
The language choice: Node.js vs. Go
Many of these systems were originally implemented in Node.js. Its event loop handles concurrent I/O operations efficiently without OS thread management overhead. A well-suited model for I/O-bound workloads. Dispatch and geospatial systems are not I/O-bound. They are CPU-bound.
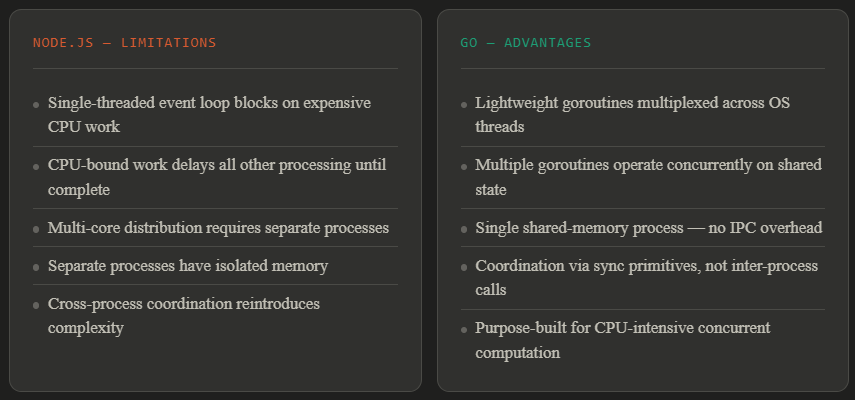
The migration from Node.js to Go for these services reflects a deliberate match between language concurrency model and workload characteristics. I/O concurrency and CPU concurrency are different problems, and Node.js and Go are optimized for different ones. By 2018, Node.js and the HTTP/JSON framework were no longer recommended at Uber. New engineers were forced to learn legacy frameworks in a different language with a non-standard protocol, increasing onboarding costs significantly.
The Fulfillment Platform rewrite
The problems with Uber's previous architecture were not limited to the geospatial and dispatch layers. The core Fulfillment Platform, the system managing the lifecycle of every ongoing trip and delivery session had been largely unchanged since 2014. Over the following decade, Uber added reservations, batch flows, airport queues, Uber Eats, Uber Direct, and more. The 2014 architecture was not built to accommodate them. After six months of auditing, 200+ pages of stakeholder requirements, and extensive benchmarking, Uber undertook a ground-up rewrite. The previous architecture's key limitations:
No extension model: Over 400 engineers modified the core platform with no clear patterns. Making changes confidently required understanding a complex, undocumented legacy system.
Ringpop scalability ceiling: Ringpop's peer-to-peer protocol imposed physical limits on ring size. Cities that crossed a concurrent trip threshold could not scale vertically within their pod.
Consistency: The entire stack was built on availability over consistency. Cassandra's last-write-wins semantics caused data corruption during split-brain scenarios and concurrent writes.
Multi-entity transactions: Writes across multiple entities were coordinated at the application layer through an arbitrary RPC mechanism. The system was internally inconsistent between operations forming a logical transaction.
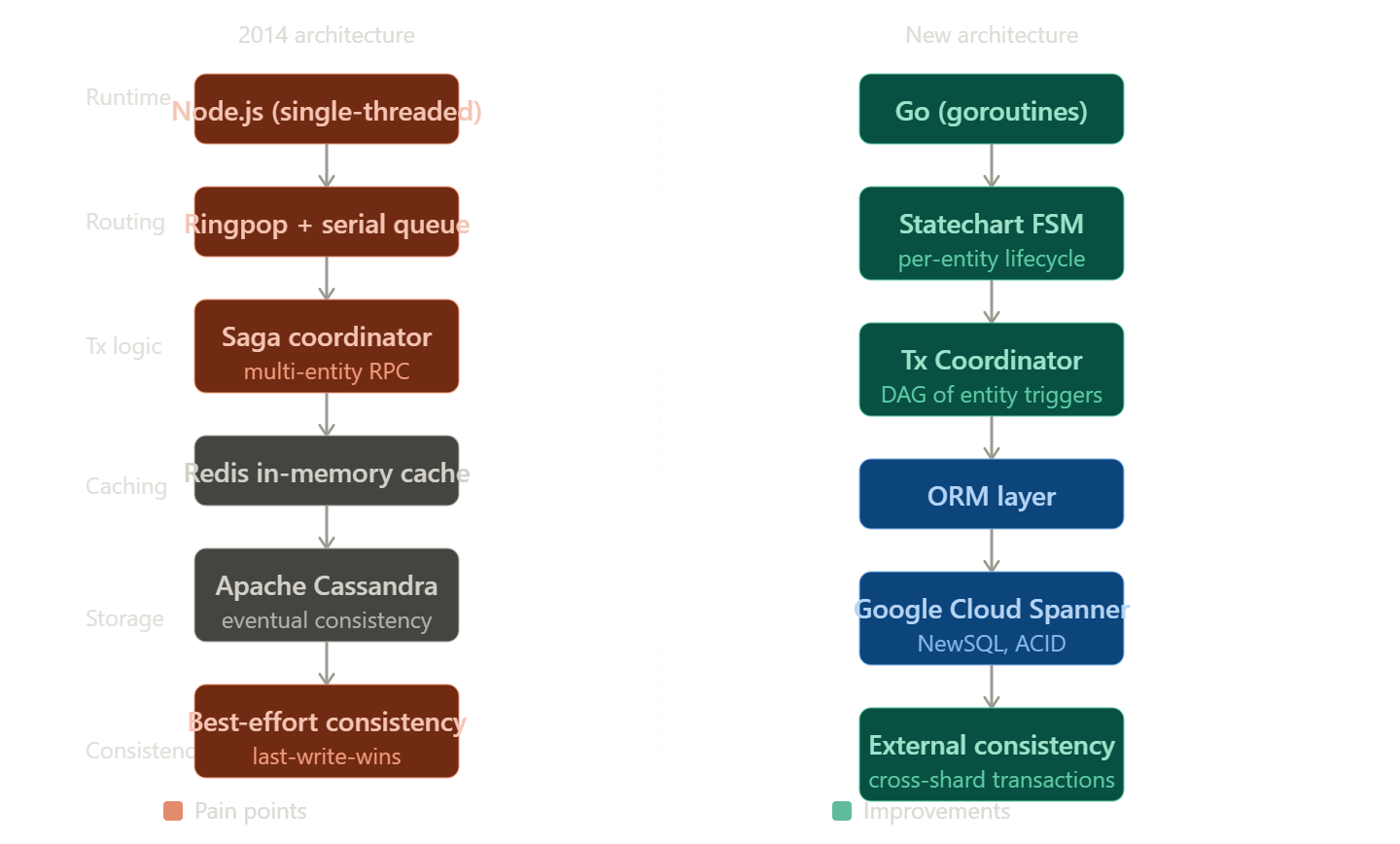
The storage decision: Google Cloud Spanner
Uber evaluated three approaches:
incrementally patching the existing NoSQL architecture
migrating to an in-house sharded MySQL solution
adopting a NewSQL database.
The requirements:
strong transactional consistency
horizontal scalability
low operational overhead
These pointed toward NewSQL. After benchmarking against criteria including availability SLA, schema management, auto-scaling, and cross-region replication, Uber selected Google Cloud Spanner.
Spanner provides external consistency, the strictest concurrency-control guarantee available along with cross-table, cross-shard ACID transactions, server-side transaction buffering, and contention and deadlock detection. These primitives eliminated entire categories of application-layer coordination logic that the previous architecture had been built to work around.
The programming model: statecharts and transaction coordination
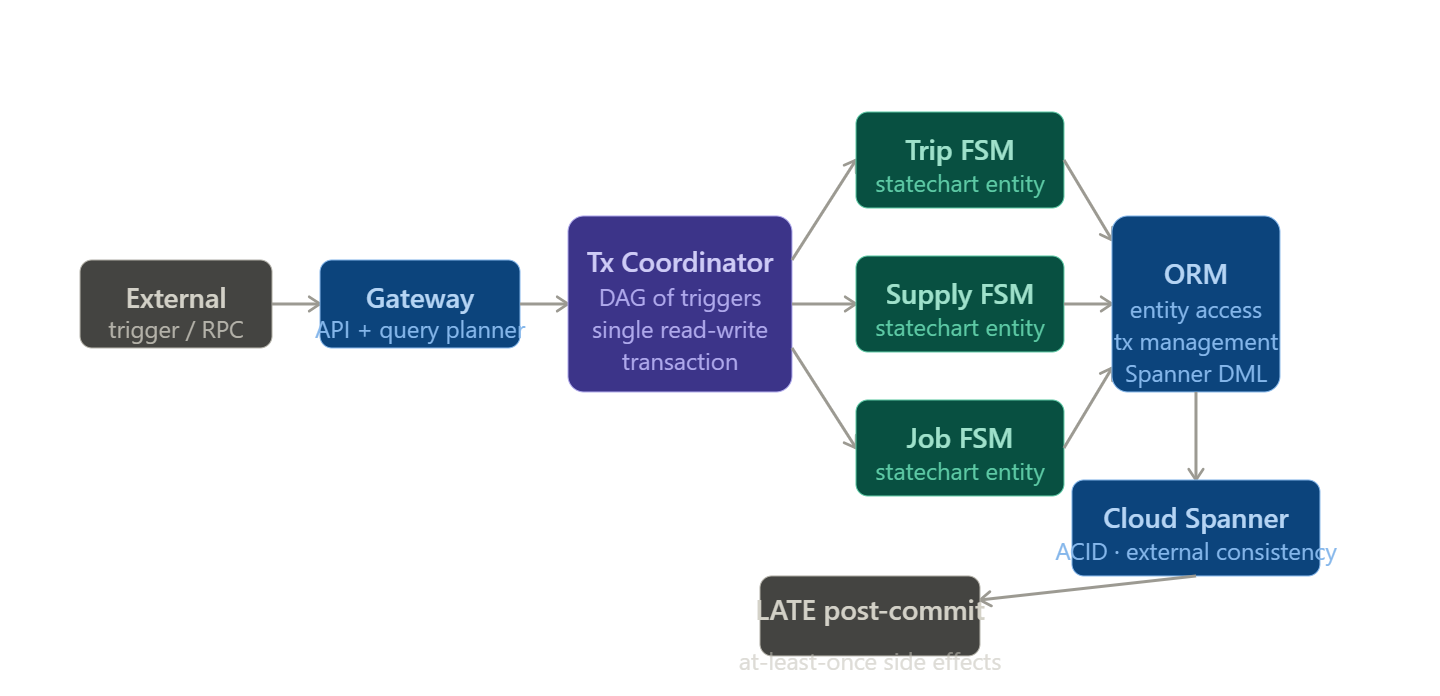
The new platform introduced three architectural layers to address extensibility. Statecharts model each fulfillment entity as a hierarchical state machine with explicit states, transitions, and triggers making entity lifecycle behavior consistent, documented, and independently testable. A Business Transaction Coordinator handles writes across multiple entities within a single read-write transaction, replacing the fragile Saga-based multi-RPC coordination of the previous system. An ORM layer provides database abstractions so engineers do not need to reason about Spanner internals when implementing product features.
