Loading blog post...

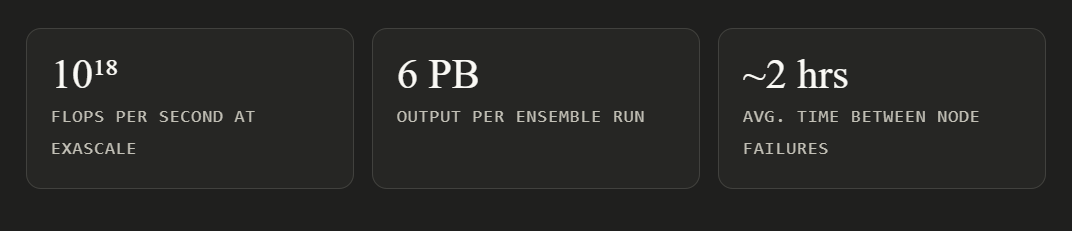
Let's start with a number: 6 petabytes. That's roughly how much raw data spills out of a single climate ensemble run, one full simulation of Earth's atmosphere, ocean, land, and ice over 4,500 simulated years. To put it plainly: that's more data than most companies will ever touch, generated by one run, on one machine, modeling one version of the future.
And the kicker? Nodes keep crashing mid-run. Like clockwork.
This is what running climate and fluid dynamics (CFD) simulations at exascale actually looks like in 2026. It's not a clean lab experiment, it's a high-stakes fight against physics, hardware, and math, all at once.
The problem isn't doing the math, it's moving the data
Here's something surprising: at this scale, raw computing power isn't really the bottleneck. You could have the fastest processor alive and it wouldn't matter if the memory can't keep up.
Think of it like cooking. You're a lightning-fast chef but your assistant takes 10 minutes to hand you each ingredient. You're standing there, idle, just waiting. That's what modern GPUs experience 80–90% of the time on these workloads.
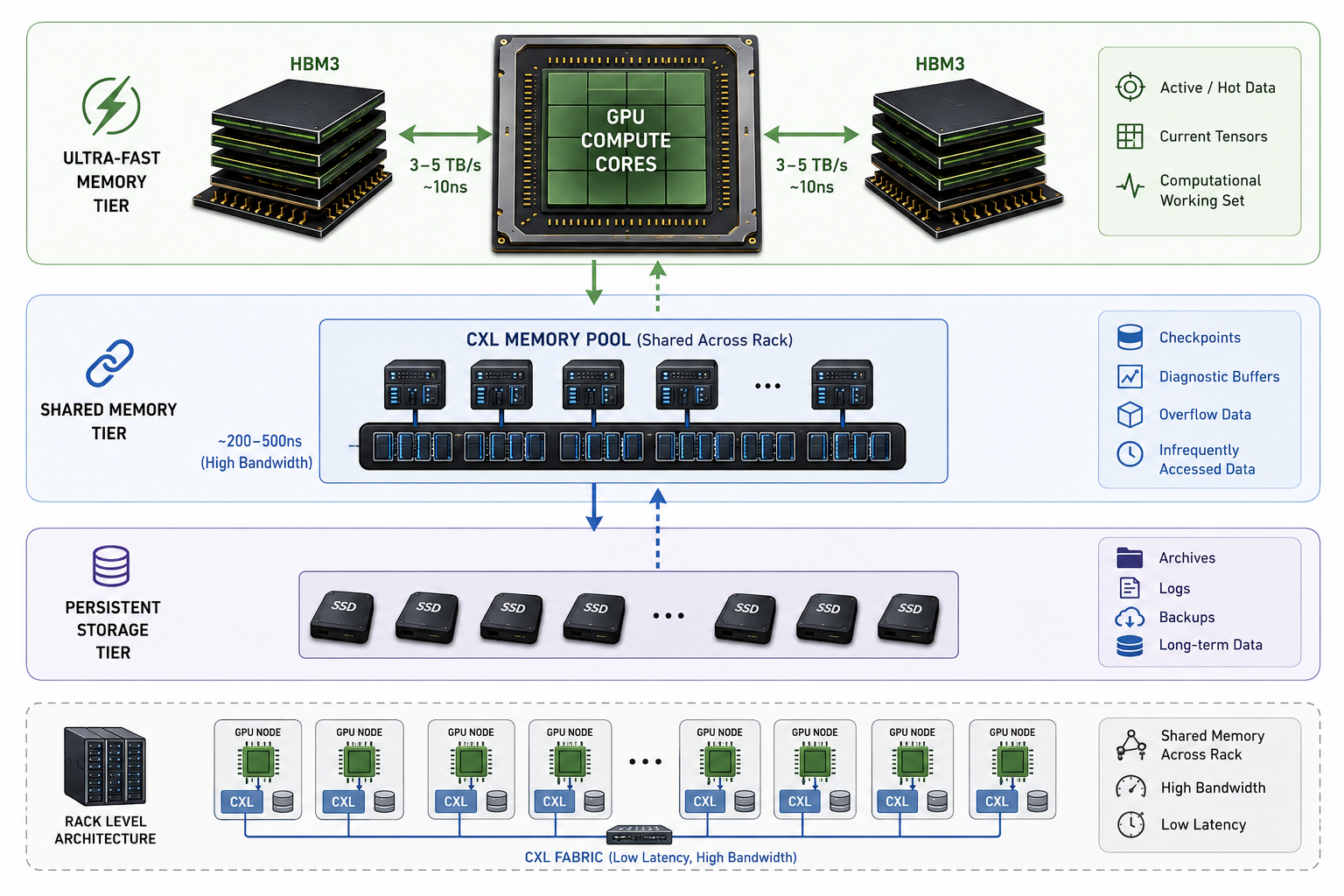
The solution the industry landed on? A multi-tier memory system. Stacked ultra-fast memory (called HBM3) lives directly on the GPU, think of it like RAM glued right onto the chip. It delivers 3–5 terabytes per second of bandwidth. For reference, your home internet tops out around 1 gigabyte. This is 5,000× faster.
But hardware alone doesn't save you. The real engineering work is knowing which data lives where. Hot computational data, the stuff your solver is actively chewing through, stays in HBM3. Checkpoints, diagnostic buffers, data you only need occasionally? Migrate it out to the slower CXL pool in the background. CXL stands for Compute Express Link - a new standard that lets racks share memory pools as if they were local. Instead of each node hoarding its own RAM, you get a shared pool across the rack, with latency around 200–500 nanoseconds. Wildly fast for what used to require disk I/O.
Get this wrong and your exaflop machine effectively runs at 200 petaflops!
Splitting the planet across 100,000 processors
Before you can run a climate simulation in parallel, you have to divide the Earth literally! The global ocean and atmosphere are broken into subdomains, one per processor (called a "rank"). Each rank works on its slice and occasionally talks to its neighbors to share border data.
This is called domain decomposition, and there are two main flavors:
Block-structured grids - Regular rectangular patches. Easy to implement, GPU-friendly. But at high resolution, some regions (eddy-rich oceans) need way more compute than calm zones leading to load imbalance where some processors sit idle.
Unstructured grids - Flexible, handles complex geometry like coastlines perfectly. Downside: memory access becomes irregular and unpredictable, which GPUs hate.
The 2026 winner is a hybrid approach powered by something called space-filling curves. A Hilbert or Morton curve is a mathematical trick that reorders your simulation cells so that nearby cells in physical space stay close in memory and on the same processor. Load balance improves dramatically. Communication volume drops 30–50%.
It sounds like a small optimization. At 100,000+ processors sharing the same ocean, it's the difference between scaling and stalling.
When nodes crash every 2 hours
On a 10,000-node exascale machine, failures aren't edge cases - they're scheduled events. Hardware dies. Cosmic rays flip bits in memory. Silent corruptions occur where the data looks fine but is subtly wrong. Expect at least one failure every 1–4 hours.
The old solution was simple: save everything to disk regularly (a "checkpoint"), and restart from there if something goes wrong. Easy on small clusters. At petabyte scale? A single checkpoint takes 30–60 minutes to write. If you checkpoint every hour, you've handed 50% of your machine's time to disaster recovery.
"Your 4,500-year simulation becomes 99% checkpoint overhead. You've built a very expensive backup machine that occasionally does science."
Modern systems like SCR (Scalable Checkpoint/Restart, from Lawrence Livermore National Lab) get smarter about this. Instead of always writing to slow parallel filesystems, SCR stages checkpoints to fast local SSDs on each node, uses parity math across racks to reconstruct lost data, and only flushes to permanent storage when safe. Checkpoints happen in layers: quick local ones every few minutes, full system checkpoints rarely.
But even that isn't the real solution at exascale. The real answer is baking resilience into the algorithms themselves.
Algorithm-level fault tolerance
This is where things get genuinely clever. The insight: most scientific computing operations have a mathematical structure you can exploit to detect and fix errors on-the-fly, without ever stopping the simulation.
The technique is called ABFT - Algorithm-Based Fault Tolerance, and it works like a checksum for your linear algebra. Before doing a big matrix computation (like solving a pressure equation or transporting tracers), you augment your data with checksum rows and columns, extra weighted sums of the real data. You run the computation on this augmented structure. When you're done, you verify: do the output checksums match what they should be mathematically?
If they don't match, you've found an error. And because you have both row and column checksums, you can pinpoint the exact corrupted element and correct it. Single error - one subtraction fixes it. Multiple errors - solve a tiny linear system from the surviving checksums.
Overhead? Less than 5% on GPUs. You're detecting and correcting hardware bit-flips on the fly, with almost no performance cost. No restart. No lost progress. Just a quiet correction and the simulation keeps running.
V-ABFT: the 2026 upgrade that changes everything
Classic ABFT had one persistent problem: false alarms. The error threshold it used to decide "is this a real corruption or just floating-point rounding noise?" was set conservatively so conservatively that on modern mixed-precision hardware (where you intentionally store data in lower precision to save memory), it would constantly flag harmless rounding as errors and trigger unnecessary restarts.
V-ABFT by Yiheng Gao et all. fixed this by making the threshold adaptive. Instead of a fixed worst-case bound, V-ABFT computes the actual statistical variance of the terms contributing to each checksum and adjusts the threshold accordingly. It ignores harmless rounding noise but catches actual neutron-induced bit-flips instantly. NCAR's CESM climate model (the flagship US global climate simulator) ported V-ABFT in March 2026. Result: false-positive restarts dropped 90%. Checkpoint overhead went from 25% of runtime to under 2%.
Quantum computing crashes the party
Now the wild card. In 2026, quantum computing is starting to become a real, if still limited tool for computational science.
The specific appeal for climate and CFD: quantum algorithms can solve certain linear systems exponentially faster than classical methods. The famous HHL algorithm (Harrow-Hassidim-Lloyd) promises O(log N) scaling for sparse matrix solves. Classical methods scale as O(N³). For the massive pressure Poisson solves in atmospheric models, this is a big deal. Early 2026 demos already ran quantum fluid dynamics simulations at 39 qubits representing 68 billion equivalent grid points. That's not science fiction — that's a paper with results.
But don't get too excited yet. Today's quantum hardware is NISQ, Noisy Intermediate-Scale Quantum. Error rates are high, qubit counts are limited, and the path to "fault-tolerant quantum" still runs through years of hardware development. Current hybrid setups offload only the hardest subproblems to quantum co-processors while classical machines handle the bulk. It's a collaboration, not a replacement.
The interesting fault-tolerance crossover: quantum error correction uses syndrome-based detection that looks remarkably similar to ABFT checksums. Early hybrid codes are already layering classical V-ABFT around quantum kernels for end-to-end resilience. The two research communities are converging.
So where does this leave us?
Barely keeping up, and it's fascinating.
The MESACLIP project at NCAR running 4,500+ simulated years of high-resolution climate data across two of the world's biggest supercomputers is the proof of concept that everything described above actually works together in production. Six petabytes of data. TC-permitting atmosphere resolution. Mesoscale-eddy-resolving oceans. All public on GDEX.
And energy is the next constraint. Modern supercomputer racks draw 500–1,000 kilowatts. Climate codes are now being rewritten to manage power dynamically throttling GPU clocks during communication phases, stretching timesteps when power budgets are tight. MESACLIP runs showed 20–30% energy savings just from smarter scheduling. Because you can build the most efficient algorithms in the world, but if the electricity bill kills the project, none of it matters.
The hardware is here. The algorithms are catching up barely. Every extra 0.01° of resolution, every extra simulated century, is a fight against physics, silicon, and the laws of parallel efficiency.
That's why people are still up at 3 a.m. tweaking variance stats and memory migration policies.