Loading blog post...

What Exactly Is Edge AI?
For most of the past decade, artificial intelligence has lived in the cloud. You speak to your smart speaker, the audio travels over the internet to a data center, a model processes it, and a response comes back. The device in your hand is little more than a microphone and speaker with a network connection.
Edge AI inverts this entirely. It is the deployment of machine learning models directly on-device, on the silicon inside your phone, earbuds, TV, dishwasher, security camera, or factory robot. So that inference happens locally, without a round trip to the cloud.
The "edge" refers to the periphery of the network. The billions of endpoints that exist outside data centers, right at the point where computation meets the physical world. Edge AI is intelligence deployed as close to the data source as physically possible.
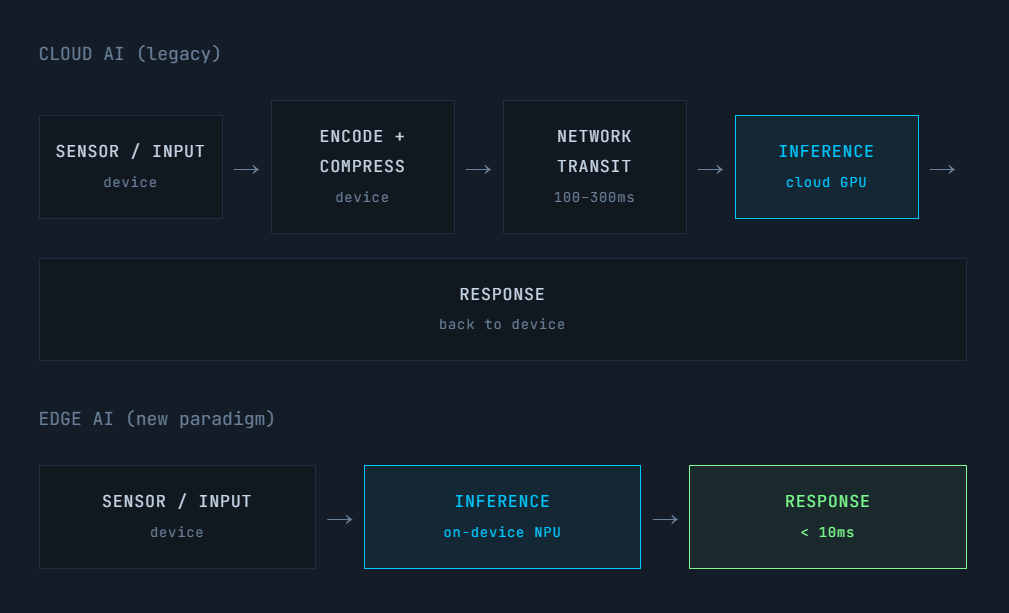
The Key Components
Edge AI is a stack of technology working together -
Neural Processing Units (NPUs): Specialized silicon designed specifically to run matrix multiplication - the core operation of neural networks with orders-of-magnitude better energy efficiency than general-purpose CPUs or GPUs. Apple's Neural Engine, Qualcomm's Hexagon, and Google's Tensor chip all fall into this category.
Model Compression Techniques: Full-sized models (GPT-4, Claude Opus, Llamma etc) require hundreds of gigabytes and thousands of watts. Getting AI onto a phone requires techniques like quantization (reducing weight precision from FP32 to INT8 or INT4), pruning (removing redundant connections), knowledge distillation (training a small model to mimic a large one), and structured sparsity.
Efficient Model Architectures. New architectures like MobileNet, EfficientNet, Mistral 7B, and Phi-3 Mini are designed from the ground up to be small and fast without sacrificing too much capability. They are the native inhabitants of edge hardware.
Inference Runtimes. Frameworks like TensorFlow Lite, ONNX Runtime, Apple's Core ML, and MediaPipe handle the low-level optimization of deploying a trained model onto heterogeneous hardware. Routing operations to the right processor (CPU, GPU, or NPU) at runtime.
Why Edge AI Changes Will defines new generation
The shift from cloud to edge will be a fundamental change in the economics, capabilities, and ethics of AI deployment. The benefits compound in ways that genuinely expand what AI can do in the world.
Ultra-Low Latency: Network round-trips to the cloud add 100–500ms of latency under ideal conditions. Far more on congested or mobile networks. On-device inference runs in single-digit milliseconds. For real-time applications like live translation, AR overlays, surgical robotics, or autonomous vehicles, this difference is the line between usable and dangerous.
Native Privacy: When data never leaves the device, there is nothing to intercept, breach, or subpoena. A health sensor that analyzes your ECG on-chip, or a keyboard that runs next-word prediction locally, processes your most sensitive data without it ever touching a server. Privacy becomes architectural, not a policy promise.
Dramatic Cost Reduction: Cloud inference is expensive. Running a billion API calls per day through a hosted LLM costs millions of dollars monthly. Edge inference, after the upfront cost of silicon, is essentially fre. One-time hardware amortized over years. At consumer scale, this is the difference between a viable product and an unsustainable burn rate.
Offline Reliability: Cloud AI dies without connectivity. A translation earpiece that stops working on a rural bus, a smart camera that goes blind when the WiFi drops, a medical device that can't analyze data in an elevator. Edge AI works anywhere, making AI-powered features genuinely reliable rather than conditionally reliable.
The Privacy Dimension Is Bigger Than You Think!
The privacy argument for edge AI deserves more than a bullet point. Consider what currently travels to the cloud: your voice every time you invoke a wake word, your face every time you unlock your phone (on some devices), your health metrics from wearables, your typing patterns, your eye movements in AR headsets.
Regulators are noticing. GDPR, CCPA, India's DPDP Act, and an expanding patchwork of AI-specific regulations are making cloud-based personal data processing increasingly expensive to comply with. Edge AI sidesteps much of this compliance burden entirely. You cannot violate data residency requirements for data that never moves.
Why Is This Happening Now?
Edge AI isn't a new idea. Researchers have dreamed of on-device intelligence since the earliest days of neural networks. What's changed is a perfect storm of hardware capability, software maturity, and business pressure converging simultaneously.

The Model Size Collapse
Perhaps the most important driver is the dramatic reduction in model size required to achieve useful capability. The implicit assumption for years was that capability scaled with size. Bigger models, smarter AI. Efficient architecture research has shattered this assumption.
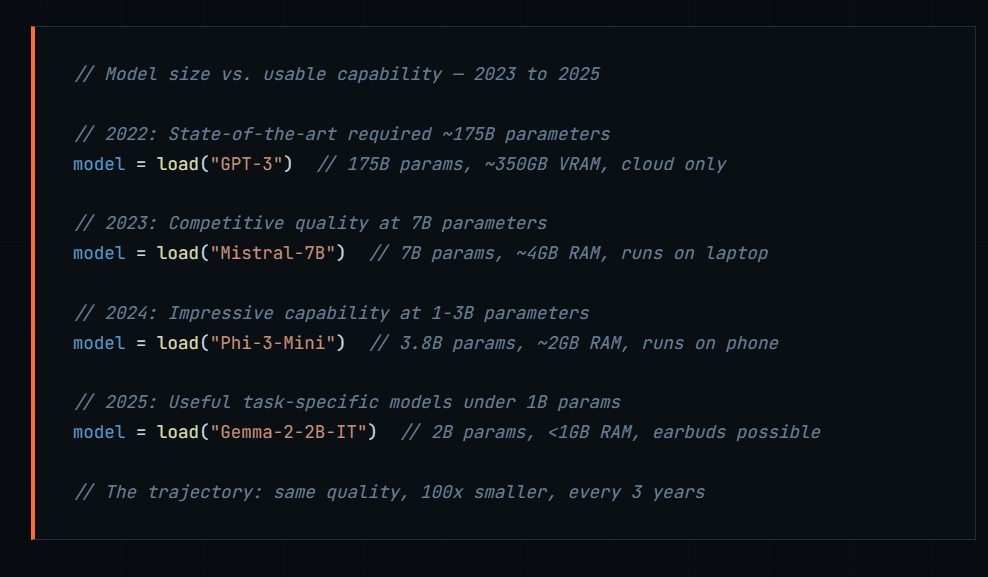
Energy Efficiency as the Hidden Driver
Battery life is the silent constraint governing all mobile AI. An NPU running a language model task can consume as little as 1–2 milliwatts. The equivalent of tens of thousands of inferences on a single charge. Modern NPUs achieve this by using fixed-function silicon that is purpose-built for the specific arithmetic of neural networks, eliminating the overhead of a general-purpose processor.
This energy efficiency is what makes always-on AI features possible. Your phone's always-on display, your smartwatch's continuous heart rate monitoring, your earbuds' ambient sound processing - all of these run on dedicated low-power silicon that makes continuous AI inference sustainable.
Beyond Phones: Where Edge AI Is Going
Smartphones were the proof-of-concept. The real story of Edge AI is a wave spreading outward from our pockets into every category of connected device — and eventually into devices that aren't even "connected" in the traditional sense.

Smartphones and Laptops: The Established Frontier - The Apple A17 Pro's Neural Engine delivers 35 TOPS (trillion operations per second). Qualcomm's Snapdragon 8 Elite hits 45 TOPS. These aren't abstract benchmark numbers. They power Apple Intelligence's on-device writing tools, live transcription, Photo cleaning, and the semantic search indexing that makes Spotlight genuinely useful. Samsung's Galaxy AI family runs Gemini Nano locally for call summaries, live translation, and note organization. On the laptop side, the AI PC category emerged in earnest in 2024. Intel's Lunar Lake and Meteor Lake architectures include dedicated NPU tiles. Qualcomm's Snapdragon X Elite, used in Microsoft's Copilot+ PCs, delivers 45 TOPS with a power envelope designed for fanless thin-and-light devices. Windows 11's Recall (contextual memory search), Cocreator (AI image generation in Paint), and Live Captions run locally on these machines.
Earbuds: The Surprising Battleground - Audio accessories are the most underestimated edge AI category. The computational constraints are extreme. A modern earbud has perhaps 1MB of RAM and a processor running at tens of megahertz, drawing power measured in microwatts. Yet remarkable AI capabilities are appearing in this form factor. Noise cancellation has been running simple ML models in earbuds for years — analyzing microphone input to predict and cancel ambient noise at audio speeds (44,100 samples per second). The new frontier is speaker separation (focusing on one voice in a crowd), personalized audio profiles fitted to your ear's geometry, and real-time translation. Amazon's Echo Buds and Sony's LinkBuds S already do continuous spatial audio adjustment using on-device models. The next generation will handle live translation entirely in the bud.
Cameras and Computer Vision = Security cameras, doorbell cameras, and industrial vision systems represent one of the highest-value edge AI deployments. The traditional model stream 24/7 video to the cloud, analyze there, generates enormous bandwidth and storage costs, and introduces latency that defeats the purpose of real-time monitoring. Modern AI cameras embed vision inference directly. They distinguish a person from a tree blowing in the wind, identify whether the person is a known face, detect if they're carrying a package — and only upload a clip plus metadata when something interesting happens. Ambarella's CV chips and Arm's Ethos NPU series power this category. The privacy and cost implications are profound: hours of footage are never transmitted or stored.
Automotive: The Highest-Stakes Edge - No domain illustrates the mandatory nature of edge AI better than autonomous driving. When a car needs to recognize a pedestrian stepping into the road, processing that frame in the cloud and receiving a response 300ms later is not an option, a car traveling at 60mph covers 8 meters in that time. All safety-critical perception must happen on-chip, in real time. Tesla's Full Self-Driving runs on their custom HW4 chips, processing camera inputs from eight cameras simultaneously. NVIDIA's DRIVE Orin (254 TOPS) and its successor Thor (2,000 TOPS) are designed as the brain of next-generation autonomous vehicles. Even non-autonomous cars now run edge AI for drowsiness detection, lane keeping, and adaptive cruise control.
The Key Players Shaping Edge AI
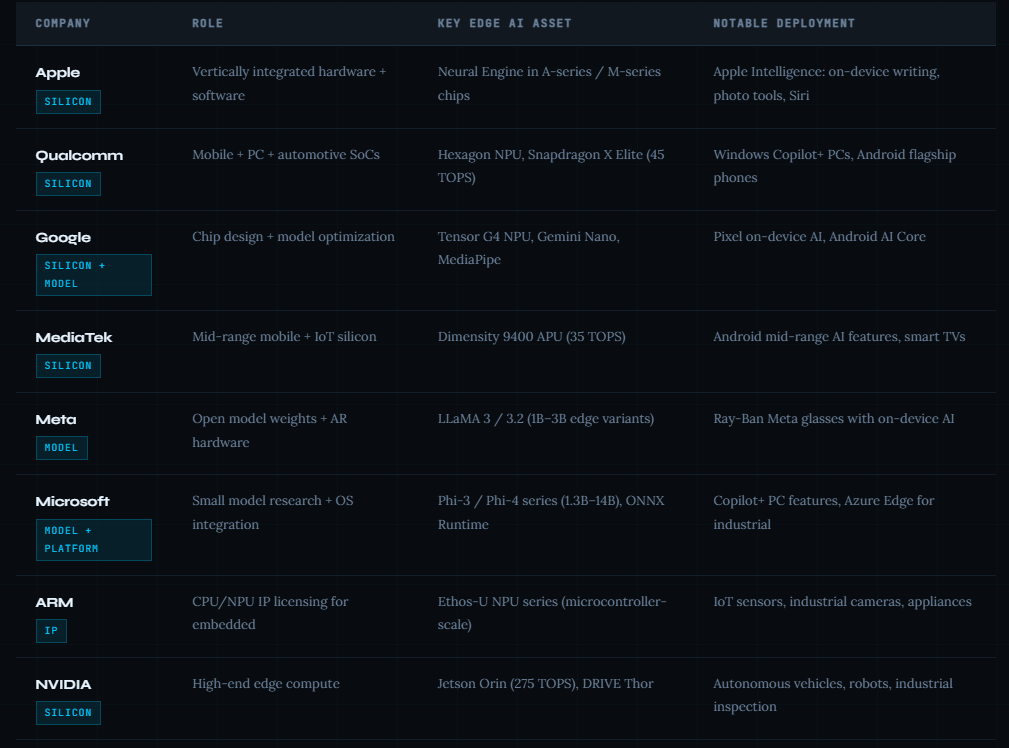
How a Model Gets to the Edge
Deploying a state-of-the-art model onto a 5W SoC is a multi-stage engineering process. Understanding it demystifies why "just put GPT-4 on a phone" isn't the answer and why the models that do run on-device are genuinely impressive engineering achievements.
Architecture Selection - The process starts long before deployment in model design. Architectures for edge devices favor depth-wise separable convolutions (MobileNet family), efficient attention mechanisms (sliding window attention in Mistral), and factorized layers. Models are often designed with specific hardware targets in mind, optimizing for the operation types an NPU handles natively.
Quantization - Standard neural network weights are stored as 32-bit floating point numbers (FP32). Quantization reduces this precision to 16-bit float (FP16), 8-bit integer (INT8), or even 4-bit integer (INT4). A model quantized to INT8 is roughly 4× smaller and runs 2–4× faster on hardware with INT8 acceleration, with typically less than 1% accuracy degradation on most benchmarks.
Pruning and Sparsity - Neural networks are typically over-parameterized. Many weights contribute minimally to output quality. Pruning identifies and zeros out these redundant weights. Structured pruning removes entire neurons, filters, or attention heads, producing a physically smaller model. Unstructured pruning produces a sparse weight matrix that requires special hardware support to exploit efficiently.
Knowledge Distillation - A large "teacher" model can train a small "student" model by providing soft probability distributions (not just hard labels) as training targets. The student learns not just the correct answers but the teacher's uncertainty structure which classes are similar, which tokens are plausible alternatives. This is how models like DistilBERT (66% of BERT's size, 97% of its capability on GLUE) are produced. Apple's on-device models are believed to use distillation from their larger server-side models.
Format Conversion and Runtime Optimization - The trained, compressed model must be compiled into a format the target hardware can execute efficiently. Apple's Core ML Tools converts PyTorch/TensorFlow models into mlmodel packages with hardware-specific graph optimizations. Qualcomm's AI Engine Direct SDK generates binaries targeting the Hexagon NPU's specific instruction set. ONNX Runtime applies graph-level optimizations like operator fusion (combining consecutive operations to reduce memory bandwidth) and constant folding.
The Obstacles
Edge AI isn't a solved problem. It's an active engineering frontier with genuine, hard constraints. Honest discussion requires acknowledging what doesn't work yet.
Context Window Limits - On-device LLMs typically support 4K–8K token context windows. Cloud models operate at 128K–1M tokens. Tasks requiring long-document analysis, extended conversations, or multi-document synthesis remain cloud-dependent for the foreseeable future.
Model Update Complexity - Cloud models can be updated silently. Edge models ship in firmware and app updates, creating version fragmentation across a device fleet. Hot-patching an on-device model for a safety issue is significantly harder than a server-side rollback.
Thermal Management - Sustained AI inference generates heat in a small package. Phones throttle NPU performance under thermal load, meaning the latency characteristics of on-device inference are non-deterministic in extended use. Earbuds and wearables have essentially zero thermal headroom.
Model Size vs. Storage - A 4-bit quantized 7B model still occupies ~4GB of device storage. On a 64GB phone, that's 6% of total capacity for a single model. Shipping multiple specialized models - one for summarization, one for image understanding, one for coding, becomes a storage engineering problem.
Quality Gap on Frontier Tasks - For everyday NLP tasks, small models have largely closed the quality gap. But complex reasoning, multi-step planning, and creative writing still show meaningful performance differences between 3B on-device models and frontier 70B+ cloud models.
Hardware Fragmentation - Unlike cloud infrastructure where you control the hardware, edge deployment means targeting hundreds of different chip configurations each with different NPU capabilities, memory constraints, and instruction sets. A model optimized for Apple's Neural Engine may need complete re-optimization for Qualcomm's Hexagon
Hybrid AI: The Real Production Answer
The most architecturally interesting development is emergence of hybrid inference systems that dynamically route tasks between edge and cloud based on complexity, latency requirements, and privacy sensitivity.
The question is never "edge or cloud?" It's "which tasks belong where, and how do we route them intelligently?"
Apple's Private Cloud Compute is the clearest example of production-grade hybrid AI. When you ask Siri something trivial , set a timer, read a message , it's handled on-device with zero network contact. When the task exceeds on-device capability, it's escalated to Apple's cloud infrastructure. Crucially, this cloud infrastructure is designed with privacy properties that approach on-device: ephemeral processing, no persistent storage, end-to-end encryption, and third-party auditing of the server code.
Google's approach with Gemini implements similar routing. The Gemini Nano model handles quick tasks on-device. The Gemini Flash model handles tasks requiring more capability. Gemini Ultra handles complex, open-ended reasoning. The routing decision happens transparently, based on task classification done locally.
This hybrid model solves what neither pure-edge nor pure-cloud can solve alone: everyday tasks get immediate, private, offline-capable responses, while genuinely complex tasks get frontier-model quality without requiring that frontier capability to live permanently on the device.
What Next
The trajectory of edge AI is clear: more capable models in smaller, more power-constrained form factors, spreading into categories that seem improbable today. Here's what the next few years look like.
Always-On Contextual AI - Ambient intelligence that passively understands your context what meeting you're in, what document you're reading, what you said five minutes ago and provides proactive assistance without explicit invocation. Requires continuous on-device inference at milliwatt power levels.
AI at Sub-Milliwatt Scale - Inference on sensors, medical implants, and environmental monitors running on harvested energy. Processing that happens inside the sensor before data is even transmitted. Neural networks with thousands of parameters, not billions but genuinely useful for anomaly detection, classification, and prediction.
In-Memory Computing - Neuromorphic and analog computing approaches that perform inference inside memory — eliminating the energy cost of moving weights from storage to compute. Potentially 100× more energy-efficient than today's digital NPUs, enabling AI in form factors that are currently impossible.
The Agentic Edge - The most consequential near-term development is the combination of edge AI with agentic AI frameworks. An agent that can perceive its environment through device sensors, reason about what to do using an on-device model, and take actions through device APIs without any cloud dependency is a qualitatively different kind of AI than a chatbot. Apple's App Intents framework is laying the groundwork for this. So is Google's Android AI Core. The vision is a device that genuinely understands your context and can take multi-step actions on your behalf: booking a restaurant based on the conversation you just had, drafting a reply based on the email thread you read, adjusting your calendar based on the traffic you're sitting in. All local. All private. All fast.
Edge AI represents something more significant than a technical optimization. It's a fundamental redistribution of where intelligence lives in the computational stack and by extension, where power over AI resides.
Cloud-centric AI concentrates intelligence at a small number of large-scale providers. Every query, every inference, every moment of AI assistance flows through infrastructure controlled by a handful of companies. Edge AI distributes intelligence outward into devices owned by individuals, embedded in infrastructure owned by municipalities, running in machines owned by manufacturers.
The cloud era of AI asked: what can we do with unlimited compute?
The edge era asks a harder question — what can we do with almost none?