Loading blog post...

It all starts with a confession, like spilling the beans at a family dinner. We've all been there—engineers slapping together microservices, replicas firing on all cylinders, everything humming along until... bam! A partial network failure turns your "bulletproof" system into a house of cards. Or replication starts acting funky, clocks drift apart like old friends losing touch, and suddenly consensus feels like herding cats in a thunderstorm. That's when this book stops being some dusty textbook and becomes your lifeline. Van Steen and Tanenbaum don't hype it up; they just lay out the plumbing manual for how these sprawling, networked beasts actually tick—and more importantly, how they trip over their own feet.
At its heart, the book paints distributed systems as this grand illusion: a bunch of independent machines pretending to be one big, happy family. "A collection of autonomous computing elements that appears as a single coherent system," they define it early on, and oh boy, does that simple line unravel into a saga of triumphs and pitfalls. Autonomy means each node can crash on its own schedule, but coherence? That's the magic trick where users never notice the seams. The tension between those two is like a thriller plot, driving every chapter forward.
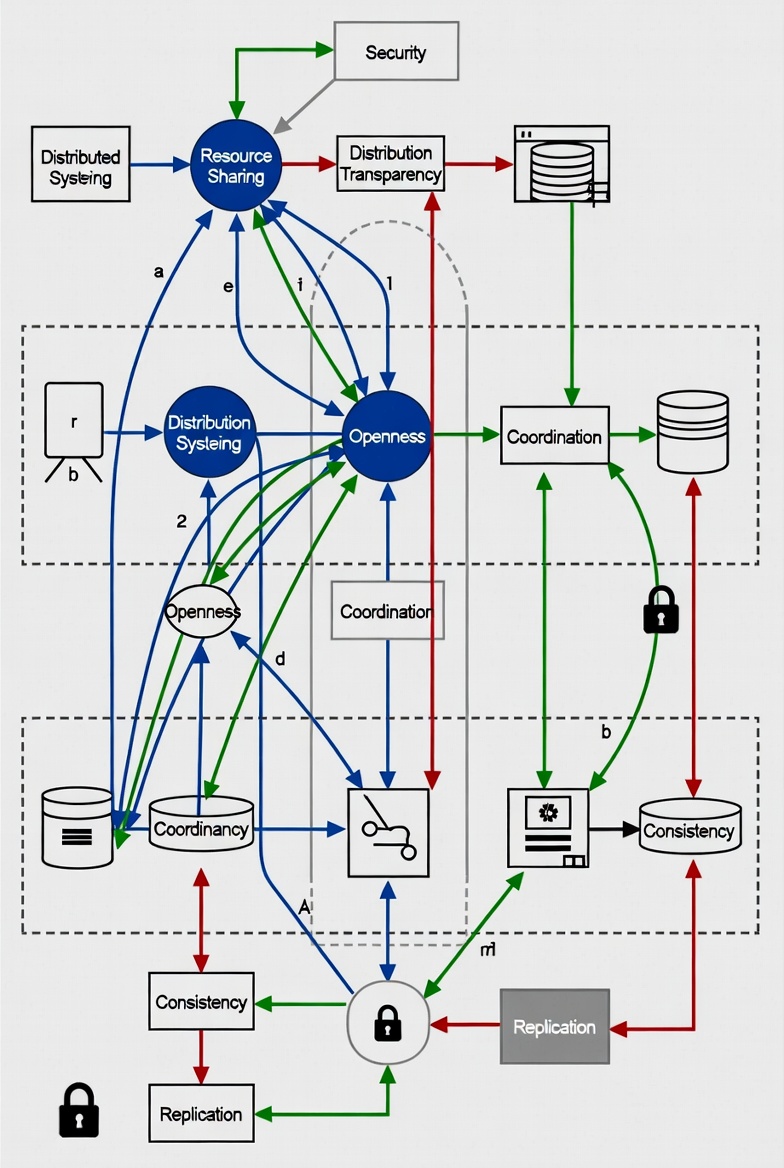
The adventure kicks off setting the philosophical ground, introducing design goals that feel like quests: resource sharing (because why hoard when you can collaborate?), distribution transparency (hiding the mess so it looks seamless), openness (play nice with others), and scalability (grow big without exploding). They dive into transparencies—access, location, replication, failure—and then cheekily question if total hiding is even wise. It's like they're winking at you: "Sure, make it invisible, but know the cost." Scalability gets broken down into size, geography, and admin dimensions, with pitfalls listed like warning signs on a treacherous path. And the types? High-performance computing clusters, info systems like transaction processors, and pervasive setups in smart devices—real-world examples that make you nod and think, "Ah, that's why my IoT gadgets flake out sometimes."
Now, we're architecting our way through the wilderness. Imagine choosing your system's skeleton: layered stacks for clean separation, object-based or service-oriented for that modular vibe, resource-based like RESTful APIs, or pub-sub for event-driven fun. Then comes the big-picture org: centralized (easy but bottleneck-prone), decentralized peer-to-peer (resilient but chatty), or hybrids blending the best. They throw in gems like NFS and the Web as case studies—NFS with its client-server dance, the Web with its stateless HTTP magic. It's not abstract; it's like dissecting a living organism, seeing how choices dictate failure modes and growth limits. If you've ever argued monolith vs. microservices over beer, this arms you with killer ammo.
Things get gritty with processes—the beating hearts of it all. Threads zoom around like hyperactive squirrels in distributed land, virtualization lets you fake entire machines (hello, VMs solving heterogeneity headaches), clients handle UI tricks and transparency hacks, servers juggle concurrency like circus pros. The Apache Web Server breakdown is a highlight—thread pools, preforking, the works—followed by server clusters and code migration tales. Why migrate code? For load balancing or optimization, but watch out for those pesky heterogeneous systems turning your bytecode into a compatibility nightmare. It's practical gold for anyone scaling backends.
Now the communication dragons awaken. Foundations lay out layered protocols (OSI vibes but distributed-flavored) and comm types. RPCs masquerade as local calls but reveal their network warts—parameter marshaling, async variants, even DCE RPC as a vintage example. Message-oriented middleware steals the show: transient sockets for quick chats, persistent queues like IBM's WebSphere or AMQP for reliable handoffs. Multicast? Tree-based, flooding, gossip—gossip-based dissemination is my favorite, spreading data like juicy rumors in a small town, resilient as hell. If you've ever debugged a flaky RPC, this feels like therapy.
Naming sounds boring. It isn’t. Flat naming with DHTs (Chord's finger tables FTW), structured like DNS hierarchies, attribute-based with LDAP directories—it's all about decoupling identifiers from addresses so things can move without breaking. Real systems like NFS and DNS get dissected, showing how resolution scales globally. Sneaky decentralized implementations add that peer-to-peer twist. Boring? Nah, it's the glue holding the illusion together.
Coordination is pure intellectual fireworks. No global clock? Enter physical sync (NTP algorithms), logical ones (Lamport's happens-before relation, vector clocks tracking causality like detectives). Mutual exclusion algorithms battle it out—centralized (simple but single-point-faily), distributed (Ricart-Agrawala's timestamp tango), token-ring, decentralized. Elections? Bully algo bullying its way to leadership, ring-based circling the wagons, even wireless and large-scale variants. Location systems throw in GPS drama and logical positioning when satellites bail. Gossip returns for aggregation and overlays—fun, epidemic-style coordination that scales effortlessly.
The consistency and replication swamp is where trade-offs bite hard. Replicate for speed and uptime, but consistency? Data-centric models (continuous bounding, sequential/total/causal ordering, eventual vibes), client-centric guarantees (monotonic reads/writes, read-your-writes). Replica management covers placement (CDNs optimizing latency), distribution, protocols like primary-based or quorum-voting. Web caching examples tie it to reality—think Akamai's edge magic. This is where you grasp why your DB feels "eventually right" and why strong consistency costs an arm and a leg.
Fault tolerance is where optimism dies—and engineering begins. Crash-stop, Byzantine models; mask with redundancy (triple modular, anyone?). Process resilience via groups, reliable multicast (atomic, ordered). Consensus? Paxos unpacked like a puzzle box, distributed commit (two-phase's commit-or-abort drama), checkpointing for recovery. It's tense, showing agreement in faulty worlds is a miracle.
Security wraps it up, securing channels, auth like Kerberos, access lists, DoS defenses. It's the fortress around your distributed kingdom.
Whew, what a journey. This book isn't a quick skim; it's a slow burn that rewires your brain. Core takeaways? Failures are inevitable, time's a liar, consistency's a spectrum, coordination's pricey, transparency's a double-edged sword. Replication fixes stuff—and breaks more. If you're slinging code in clouds, designing systems, or just geeking out, grab it. You'll emerge not flashy, but formidable, asking the right questions: "What's the failure model? Clock drift handling? Partition behavior?" In a world of hype, this is the real deal—jolly in its depth, fun in its revelations, and technically razor-sharp. Dive in; the network's waiting.
Core Concepts Summarized
Let’s compress the heart of the book:
Distributed systems are about illusion: many machines acting as one.
Failures are normal, not exceptional.
Time is unreliable.
Consistency is a design choice, not a guarantee.
Scalability has size, geographic, and administrative dimensions.
Coordination is expensive.
Transparency is costly.
Replication solves problems — and creates new ones.
If you internalize these, you think differently.
Why You Should Read It
Because every modern backend is distributed. Cloud-native? Distributed. Microservices? Distributed. Databases with replicas? Distributed. Kafka? Distributed. CDNs? Distributed.
If you don’t understand the fundamentals, you’re just stitching APIs together and hoping for the best. This book gives you mental models.
And once you have those, systems stop feeling magical — and start feeling predictable.
Who Should Read This
1. Backend Engineers
If you work with distributed databases, queues, clusters, or cloud services — this is foundational.
2. System Designers
If you architect large-scale systems, you need this mental toolkit.
3. DevOps / SRE
Understanding failure modes, replication, and coordination is your daily bread.
4. Computer Science Students
This is a serious textbook — structured and rigorous.
5. Curious Engineers
If you like understanding how things really work under the hood — you’ll enjoy it.